The source files can be found in examples/.
Example 11: Hyper parameter tuning
Hyper parameter tuning is a powerful technique to choose parameters based on their performance on test folds. In this example, we will showcase the two implemented approaches implemented in PortfolioOptimisers.jl.
using PortfolioOptimisers, PrettyTables
# Format for pretty tables.
tsfmt = (v, i, j) -> begin
if j == 1
return Date(v)
else
return v
end
end;
resfmt = (v, i, j) -> begin
if j == 1
return v
else
return isa(v, Number) ? "$(round(v*100, digits=3)) %" : v
end
end;1. Setting up
For this example, we will use 5 years of daily data. This is so that we have enough data to perform cross validation on significant amounts of data for both training and testing.
Cross validation cannot have precomputed values like we have done in previous examples. This is because the training and testing sets are generated on the fly, and the performance metrics are computed based on the results of the optimization on these sets.
using CSV, TimeSeries, DataFrames, Clarabel, Statistics, StableRNGs, Distributions
X = TimeArray(CSV.File(joinpath(@__DIR__, "SP500.csv.gz")); timestamp = :Date)[(end - 252 * 5):end]
pretty_table(X[(end - 5):end]; formatters = [tsfmt])
# Compute the returns
rd = prices_to_returns(X)
slv = [Solver(; name = :clarabel1, solver = Clarabel.Optimizer,
settings = Dict("verbose" => false),
check_sol = (; allow_local = true, allow_almost = true)),
Solver(; name = :clarabel2, solver = Clarabel.Optimizer,
settings = Dict("verbose" => false, "max_step_fraction" => 0.95),
check_sol = (; allow_local = true, allow_almost = true)),
Solver(; name = :clarabel3, solver = Clarabel.Optimizer,
settings = Dict("verbose" => false, "max_step_fraction" => 0.9),
check_sol = (; allow_local = true, allow_almost = true)),
Solver(; name = :clarabel4, solver = Clarabel.Optimizer,
settings = Dict("verbose" => false, "max_step_fraction" => 0.85),
check_sol = (; allow_local = true, allow_almost = true)),
Solver(; name = :clarabel5, solver = Clarabel.Optimizer,
settings = Dict("verbose" => false, "max_step_fraction" => 0.8),
check_sol = (; allow_local = true, allow_almost = true)),
Solver(; name = :clarabel6, solver = Clarabel.Optimizer,
settings = Dict("verbose" => false, "max_step_fraction" => 0.75),
check_sol = (; allow_local = true, allow_almost = true)),
Solver(; name = :clarabel7, solver = Clarabel.Optimizer,
settings = Dict("verbose" => false, "max_step_fraction" => 0.70),
check_sol = (; allow_local = true, allow_almost = true))];┌────────────┬─────────┬─────────┬─────────┬─────────┬─────────┬─────────┬──────
│ timestamp │ AAPL │ AMD │ BAC │ BBY │ CVX │ GE │ ⋯
│ Date │ Float64 │ Float64 │ Float64 │ Float64 │ Float64 │ Float64 │ Flo ⋯
├────────────┼─────────┼─────────┼─────────┼─────────┼─────────┼─────────┼──────
│ 2022-12-20 │ 131.916 │ 65.05 │ 31.729 │ 77.371 │ 169.497 │ 62.604 │ 310 ⋯
│ 2022-12-21 │ 135.057 │ 67.68 │ 32.212 │ 78.729 │ 171.49 │ 64.67 │ 314 ⋯
│ 2022-12-22 │ 131.846 │ 63.86 │ 31.927 │ 78.563 │ 168.918 │ 63.727 │ 311 ⋯
│ 2022-12-23 │ 131.477 │ 64.52 │ 32.005 │ 79.432 │ 174.14 │ 63.742 │ 314 ⋯
│ 2022-12-27 │ 129.652 │ 63.27 │ 32.065 │ 79.93 │ 176.329 │ 64.561 │ 314 ⋯
│ 2022-12-28 │ 125.674 │ 62.57 │ 32.301 │ 78.279 │ 173.728 │ 63.883 │ 31 ⋯
└────────────┴─────────┴─────────┴─────────┴─────────┴─────────┴─────────┴──────
14 columns omitted2. Hyper parameter tuning
For this tutorial we will use the Stacking estimator, but the hyper parameter tuning works for every optimisation estimator. All you need is to use the right propertynames and indexing to access the parameters you want to tune. They use Julia's built-in parsing to create the lenses used by Accessors.jl to update the immutable estimators.
The parameter tuning uses a scoring function, a scoring metric (a risk measure), and an appropriate cross validation estimator. Only estimators which have a 1 to 1 ratio of training to test sets can be used, so only KFold and WalkForwardEstimator and their results can be used. This may be expanded in the future, using a similar technique for choosing the best path similarly to how it's done for the NestedClustered and Stacking estimators.
opt = JuMPOptimiser(; slv = slv)
r = MeanReturnRiskRatio(; rk = LowOrderMoment(; alg = SecondMoment()))
st = Stacking(; opti = [MeanRisk(; opt = opt), RiskBudgeting(; opt = opt)],
opto = MeanRisk(; opt = opt))Stacking
pe ┼ EmpiricalPrior
│ ce ┼ PortfolioOptimisersCovariance
│ │ ce ┼ Covariance
│ │ │ me ┼ SimpleExpectedReturns
│ │ │ │ w ┴ nothing
│ │ │ ce ┼ GeneralCovariance
│ │ │ │ ce ┼ SimpleCovariance: SimpleCovariance(true)
│ │ │ │ w ┴ nothing
│ │ │ alg ┴ Full()
│ │ mp ┼ MatrixProcessing
│ │ │ pdm ┼ Posdef
│ │ │ │ alg ┼ UnionAll: NearestCorrelationMatrix.Newton
│ │ │ │ kwargs ┴ @NamedTuple{}: NamedTuple()
│ │ │ dn ┼ nothing
│ │ │ dt ┼ nothing
│ │ │ alg ┼ nothing
│ │ │ order ┴ NTuple{4, Symbol}: (:pdm, :dn, :dt, :alg)
│ me ┼ SimpleExpectedReturns
│ │ w ┴ nothing
│ horizon ┴ nothing
wb ┼ nothing
fees ┼ nothing
sets ┼ nothing
scale ┼ nothing
opti ┼ 2-element Vector{RiskJuMPOptimisationEstimator}
│ MeanRisk ⋯
│ RiskBudgeting ⋯
opto ┼ MeanRisk
│ opt ┼ JuMPOptimiser
│ │ pe ┼ EmpiricalPrior
│ │ │ ce ┼ PortfolioOptimisersCovariance
│ │ │ │ ce ┼ Covariance
│ │ │ │ │ me ┼ SimpleExpectedReturns
│ │ │ │ │ │ w ┴ nothing
│ │ │ │ │ ce ┼ GeneralCovariance
│ │ │ │ │ │ ce ┼ SimpleCovariance: SimpleCovariance(true)
│ │ │ │ │ │ w ┴ nothing
│ │ │ │ │ alg ┴ Full()
│ │ │ │ mp ┼ MatrixProcessing
│ │ │ │ │ pdm ┼ Posdef
│ │ │ │ │ │ alg ┼ UnionAll: NearestCorrelationMatrix.Newton
│ │ │ │ │ │ kwargs ┴ @NamedTuple{}: NamedTuple()
│ │ │ │ │ dn ┼ nothing
│ │ │ │ │ dt ┼ nothing
│ │ │ │ │ alg ┼ nothing
│ │ │ │ │ order ┴ NTuple{4, Symbol}: (:pdm, :dn, :dt, :alg)
│ │ │ me ┼ SimpleExpectedReturns
│ │ │ │ w ┴ nothing
│ │ │ horizon ┴ nothing
│ │ slv ┼ 7-element Vector{Solver}
│ │ │ Solver ⋯
│ │ │ Solver ⋯
│ │ │ Solver ⋯
│ │ │ Solver ⋯
│ │ │ Solver ⋯
│ │ │ Solver ⋯
│ │ │ Solver ⋯
│ │ wb ┼ WeightBounds
│ │ │ lb ┼ Float64: 0.0
│ │ │ ub ┴ Float64: 1.0
│ │ bgt ┼ Float64: 1.0
│ │ sbgt ┼ nothing
│ │ lt ┼ nothing
│ │ st ┼ nothing
│ │ lcse ┼ nothing
│ │ cte ┼ nothing
│ │ gcarde ┼ nothing
│ │ sgcarde ┼ nothing
│ │ smtx ┼ nothing
│ │ sgmtx ┼ nothing
│ │ slt ┼ nothing
│ │ sst ┼ nothing
│ │ sglt ┼ nothing
│ │ sgst ┼ nothing
│ │ tn ┼ nothing
│ │ fees ┼ nothing
│ │ sets ┼ nothing
│ │ tr ┼ nothing
│ │ ple ┼ nothing
│ │ ret ┼ ArithmeticReturn
│ │ │ ucs ┼ nothing
│ │ │ lb ┼ nothing
│ │ │ mu ┴ nothing
│ │ sca ┼ SumScalariser()
│ │ ccnt ┼ nothing
│ │ cobj ┼ nothing
│ │ sc ┼ Int64: 1
│ │ so ┼ Int64: 1
│ │ ss ┼ nothing
│ │ card ┼ nothing
│ │ scard ┼ nothing
│ │ nea ┼ nothing
│ │ l1 ┼ nothing
│ │ l2 ┼ nothing
│ │ linf ┼ nothing
│ │ lp ┼ nothing
│ │ brt ┼ Bool: false
│ │ cle_pr ┼ Bool: true
│ │ strict ┴ Bool: false
│ r ┼ Variance
│ │ settings ┼ RiskMeasureSettings
│ │ │ scale ┼ Float64: 1.0
│ │ │ ub ┼ nothing
│ │ │ rke ┴ Bool: true
│ │ sigma ┼ nothing
│ │ chol ┼ nothing
│ │ rc ┼ nothing
│ │ alg ┴ SquaredSOCRiskExpr()
│ obj ┼ MinimumRisk()
│ wi ┼ nothing
│ fb ┴ nothing
cv ┼ nothing
wf ┼ IterativeWeightFinaliser
│ iter ┴ Int64: 100
ex ┼ Transducers.ThreadedEx{@NamedTuple{}}: Transducers.ThreadedEx()
fb ┼ nothing
brt ┼ Bool: false
strict ┴ Bool: false2.1 Grid cross validation search
GridSearchCrossValidation performs an exhaustive search over a specified parameter grid via search_cross_validation. It evaluates the performance of each combination of parameters and selects the best one based on how each point in the grid performs on the test folds.
The parameter grid can be specified as a vector of pairs where the first item is the string representation of the parameter to modify, the second is a vector with the range to try. Alternatively one can use a dictionary where the items are these pairs. The function will compute the product of the grid to create the full parameter grid. When using a dictionary, the order of the parameters is not guaranteed, but this makes no difference to the grid search, it does for the randomised search, so if using the latter use an OrderedDict from OrderedCollections or a vector of vectors instead.
It is possible to provide a vector of grids, where each grid will be computed independently and then concatenated into a single search space. This allows for the specification of multiple different grids simultaneously.
Due to the typing system, if using a vector of vectors you have to call concrete_typed_array to ensure the correct type is inferred, alternatively use a vector of dictionaries.
Here we will search three grids, the final score will reflect the best performing parameter combination among all grids.
p = concrete_typed_array([["opti[2].opt.l1" =>
range(; start = 0.0005, stop = 0.0008, length = 3),
"opti[1].opt.l2" =>
range(; start = 0.0004, stop = 0.0007, length = 3)],
["opti[1].opt.l2" =>
range(; start = 0.0004, stop = 0.0007, length = 3)],
["opti[2].opt.l1" =>
range(; start = 0.0009, stop = 0.0012, length = 3)],
["opti[2]" => [MeanRisk(; opt = opt, obj = MaximumUtility()),
MeanRisk(; opt = opt, obj = MaximumRatio())]]])
gs_cv = GridSearchCrossValidation(p; r = r)GridSearchCrossValidation
p ┼ 4-element Vector{Union{Vector{Pair{String, StepRangeLen{Float64, Base.TwicePrecision{Float64}, Base.TwicePrecision{Float64}, Int64}}}, Vector{Pair{String, Vector{MeanRisk{JuMPOptimiser{EmpiricalPrior{PortfolioOptimisersCovariance{Covariance{SimpleExpectedReturns{Nothing}, GeneralCovariance{SimpleCovariance, Nothing}, Full}, MatrixProcessing{Posdef{UnionAll, @NamedTuple{}}, Nothing, Nothing, Nothing, NTuple{4, Symbol}}}, SimpleExpectedReturns{Nothing}, Nothing}, Vector{Solver{Symbol, UnionAll, __T_settings, @NamedTuple{allow_local::Bool, allow_almost::Bool}, Bool} where __T_settings}, WeightBounds{Float64, Float64}, Float64, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, ArithmeticReturn{Nothing, Nothing, Nothing}, SumScalariser, Nothing, Nothing, Int64, Int64, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, Bool, Bool, Bool}, Variance{RiskMeasureSettings{Float64, Nothing, Bool}, Nothing, Nothing, Nothing, SquaredSOCRiskExpr}, __T_obj, Nothing, Nothing} where __T_obj}}}}}
cv ┼ KFold
│ n ┼ Int64: 5
│ purged_size ┼ Int64: 0
│ embargo_size ┴ Int64: 0
r ┼ MeanReturnRiskRatio
│ rt ┼ MeanReturn
│ │ w ┼ nothing
│ │ flag ┴ Bool: false
│ rk ┼ LowOrderMoment
│ │ settings ┼ RiskMeasureSettings
│ │ │ scale ┼ Float64: 1.0
│ │ │ ub ┼ nothing
│ │ │ rke ┴ Bool: true
│ │ w ┼ nothing
│ │ mu ┼ nothing
│ │ alg ┼ SecondMoment
│ │ │ ve ┼ SimpleVariance
│ │ │ │ me ┼ nothing
│ │ │ │ w ┼ nothing
│ │ │ │ corrected ┴ Bool: true
│ │ │ alg1 ┼ Full()
│ │ │ alg2 ┴ SquaredSOCRiskExpr()
│ rf ┴ Float64: 0.0
scorer ┼ HighestMeanScore()
ex ┼ Transducers.ThreadedEx{@NamedTuple{}}: Transducers.ThreadedEx()
train_score ┼ Bool: false
kwargs ┴ @NamedTuple{}: NamedTuple()Now we can run the grid search cross validation. The result returns the best optimiser, the matrix of test scores, an optional matrix of training scores, the lens and value grids of the searched parameters (in vector form), and the index of the best performing parameters. The number of points in the lens and value grids is equal to the sum of the products of each grid, sum([3x3, 3x1, 3x1, 2x1]) == 17.
gs_res1 = search_cross_validation(st, gs_cv, rd)SearchCrossValidationResult
opt ┼ Stacking
│ pe ┼ EmpiricalPrior
│ │ ce ┼ PortfolioOptimisersCovariance
│ │ │ ce ┼ Covariance
│ │ │ │ me ┼ SimpleExpectedReturns
│ │ │ │ │ w ┴ nothing
│ │ │ │ ce ┼ GeneralCovariance
│ │ │ │ │ ce ┼ SimpleCovariance: SimpleCovariance(true)
│ │ │ │ │ w ┴ nothing
│ │ │ │ alg ┴ Full()
│ │ │ mp ┼ MatrixProcessing
│ │ │ │ pdm ┼ Posdef
│ │ │ │ │ alg ┼ UnionAll: NearestCorrelationMatrix.Newton
│ │ │ │ │ kwargs ┴ @NamedTuple{}: NamedTuple()
│ │ │ │ dn ┼ nothing
│ │ │ │ dt ┼ nothing
│ │ │ │ alg ┼ nothing
│ │ │ │ order ┴ NTuple{4, Symbol}: (:pdm, :dn, :dt, :alg)
│ │ me ┼ SimpleExpectedReturns
│ │ │ w ┴ nothing
│ │ horizon ┴ nothing
│ wb ┼ nothing
│ fees ┼ nothing
│ sets ┼ nothing
│ scale ┼ nothing
│ opti ┼ 2-element Vector{RiskJuMPOptimisationEstimator}
│ │ MeanRisk ⋯
│ │ RiskBudgeting ⋯
│ opto ┼ MeanRisk
│ │ opt ┼ JuMPOptimiser
│ │ │ pe ┼ EmpiricalPrior
│ │ │ │ ce ┼ PortfolioOptimisersCovariance
│ │ │ │ │ ce ┼ Covariance
│ │ │ │ │ │ me ┼ SimpleExpectedReturns
│ │ │ │ │ │ │ w ┴ nothing
│ │ │ │ │ │ ce ┼ GeneralCovariance
│ │ │ │ │ │ │ ce ┼ SimpleCovariance: SimpleCovariance(true)
│ │ │ │ │ │ │ w ┴ nothing
│ │ │ │ │ │ alg ┴ Full()
│ │ │ │ │ mp ┼ MatrixProcessing
│ │ │ │ │ │ pdm ┼ Posdef
│ │ │ │ │ │ │ alg ┼ UnionAll: NearestCorrelationMatrix.Newton
│ │ │ │ │ │ │ kwargs ┴ @NamedTuple{}: NamedTuple()
│ │ │ │ │ │ dn ┼ nothing
│ │ │ │ │ │ dt ┼ nothing
│ │ │ │ │ │ alg ┼ nothing
│ │ │ │ │ │ order ┴ NTuple{4, Symbol}: (:pdm, :dn, :dt, :alg)
│ │ │ │ me ┼ SimpleExpectedReturns
│ │ │ │ │ w ┴ nothing
│ │ │ │ horizon ┴ nothing
│ │ │ slv ┼ 7-element Vector{Solver}
│ │ │ │ Solver ⋯
│ │ │ │ Solver ⋯
│ │ │ │ Solver ⋯
│ │ │ │ Solver ⋯
│ │ │ │ Solver ⋯
│ │ │ │ Solver ⋯
│ │ │ │ Solver ⋯
│ │ │ wb ┼ WeightBounds
│ │ │ │ lb ┼ Float64: 0.0
│ │ │ │ ub ┴ Float64: 1.0
│ │ │ bgt ┼ Float64: 1.0
│ │ │ sbgt ┼ nothing
│ │ │ lt ┼ nothing
│ │ │ st ┼ nothing
│ │ │ lcse ┼ nothing
│ │ │ cte ┼ nothing
│ │ │ gcarde ┼ nothing
│ │ │ sgcarde ┼ nothing
│ │ │ smtx ┼ nothing
│ │ │ sgmtx ┼ nothing
│ │ │ slt ┼ nothing
│ │ │ sst ┼ nothing
│ │ │ sglt ┼ nothing
│ │ │ sgst ┼ nothing
│ │ │ tn ┼ nothing
│ │ │ fees ┼ nothing
│ │ │ sets ┼ nothing
│ │ │ tr ┼ nothing
│ │ │ ple ┼ nothing
│ │ │ ret ┼ ArithmeticReturn
│ │ │ │ ucs ┼ nothing
│ │ │ │ lb ┼ nothing
│ │ │ │ mu ┴ nothing
│ │ │ sca ┼ SumScalariser()
│ │ │ ccnt ┼ nothing
│ │ │ cobj ┼ nothing
│ │ │ sc ┼ Int64: 1
│ │ │ so ┼ Int64: 1
│ │ │ ss ┼ nothing
│ │ │ card ┼ nothing
│ │ │ scard ┼ nothing
│ │ │ nea ┼ nothing
│ │ │ l1 ┼ nothing
│ │ │ l2 ┼ nothing
│ │ │ linf ┼ nothing
│ │ │ lp ┼ nothing
│ │ │ brt ┼ Bool: false
│ │ │ cle_pr ┼ Bool: true
│ │ │ strict ┴ Bool: false
│ │ r ┼ Variance
│ │ │ settings ┼ RiskMeasureSettings
│ │ │ │ scale ┼ Float64: 1.0
│ │ │ │ ub ┼ nothing
│ │ │ │ rke ┴ Bool: true
│ │ │ sigma ┼ nothing
│ │ │ chol ┼ nothing
│ │ │ rc ┼ nothing
│ │ │ alg ┴ SquaredSOCRiskExpr()
│ │ obj ┼ MinimumRisk()
│ │ wi ┼ nothing
│ │ fb ┴ nothing
│ cv ┼ nothing
│ wf ┼ IterativeWeightFinaliser
│ │ iter ┴ Int64: 100
│ ex ┼ Transducers.ThreadedEx{@NamedTuple{}}: Transducers.ThreadedEx()
│ fb ┼ nothing
│ brt ┼ Bool: false
│ strict ┴ Bool: false
test_scores ┼ 5×17 Matrix{Float64}
train_scores ┼ nothing
lens_grid ┼ 17-element Vector{Vector{ComposedFunction{O, Accessors.PropertyLens{:opti}} where O}}
val_grid ┼ 17-element Vector{Tuple{Any, Vararg{Float64}}}
idx ┴ Int64: 6We can view the best indices and lenses, and that they match the chosen optimiser.
pretty_table(DataFrame("Lens" => gs_res1.lens_grid[gs_res1.idx],
"Value" => collect(gs_res1.val_grid[gs_res1.idx])))
for (lens, val) in zip(gs_res1.lens_grid[gs_res1.idx], gs_res1.val_grid[gs_res1.idx])
println("$(lpad("lens:", 12)) $lens\n$(lpad("val:", 12)) $val\n$(lpad("Field value:", 12)) $(lens(gs_res1.opt))\n")
end┌────────────────────────────────────────────────────────────┬─────────┐
│ Lens │ Value │
│ ComposedFunction{O, Accessors.PropertyLens{:opti}} where O │ Float64 │
├────────────────────────────────────────────────────────────┼─────────┤
│ _.opti[2].opt.l1 │ 0.0008 │
│ _.opti[1].opt.l2 │ 0.00055 │
└────────────────────────────────────────────────────────────┴─────────┘
lens: (@o _.opti[2].opt.l1)
val: 0.0008
Field value: 0.0008
lens: (@o _.opti[1].opt.l2)
val: 0.00055
Field value: 0.00055We can now optimise the best estimator on the full dataset to inspect the resulting portfolio.
using StatsPlots, GraphRecipes
res_gs1 = optimise(gs_res1.opt, rd)
plot_composition(res_gs1, rd)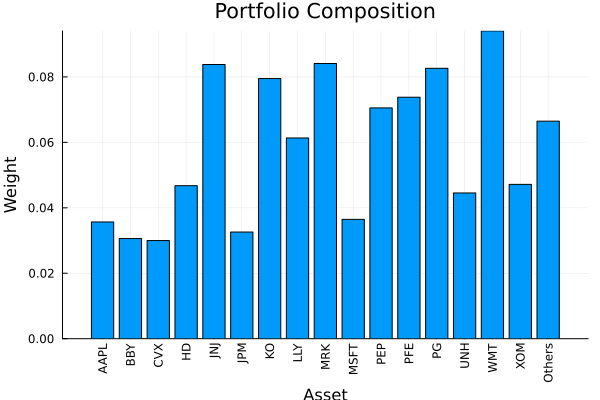
2.2 Randomised cross validation search
RandomisedSearchCrossValidation performs an randomised search over a sampled parameter grid via search_cross_validation. It can take the same type of grid as GridSearchCrossValidation, in which case the parameters are sampled without replacement. It can also take a subtype of Distributions.Distribution instead of a vector of values, in which case any parameters given as a vector will be sampled with replacement. The property n_iter defines the number of samples to draw from the vectors or distributions. When sampling without replacement, the sampling is performed up until the list of candidates is exhausted, so the maximum number of samples drawn from a list is min(n_iter, length(list)). After the parameters have been sampled, a grid search cross validation is performed. It's also possible to provide a vector of grids, which works exactly like GridSearchCrossValidation.
It is important to note that sampling uses the random state, so the order of the parameters will affect the sampling of distributions and sets of values. To ensure reproducibility, use an ordered dictionary or a vector for each grid, and don't change the order of parameters in each grid, or the order of the grids.
2.2.1 Sampling from a predefined parameter space
First let's sample from the predefined parameter space. This will only sample two parameters from each grid, because all parameters were given as lists, the sampling is without replacement so parameters cannot be sampled twice.
rs_cv1 = RandomisedSearchCrossValidation(p; rng = StableRNG(42), r = r, n_iter = 2)RandomisedSearchCrossValidation
p ┼ 4-element Vector{Union{Vector{Pair{String, StepRangeLen{Float64, Base.TwicePrecision{Float64}, Base.TwicePrecision{Float64}, Int64}}}, Vector{Pair{String, Vector{MeanRisk{JuMPOptimiser{EmpiricalPrior{PortfolioOptimisersCovariance{Covariance{SimpleExpectedReturns{Nothing}, GeneralCovariance{SimpleCovariance, Nothing}, Full}, MatrixProcessing{Posdef{UnionAll, @NamedTuple{}}, Nothing, Nothing, Nothing, NTuple{4, Symbol}}}, SimpleExpectedReturns{Nothing}, Nothing}, Vector{Solver{Symbol, UnionAll, __T_settings, @NamedTuple{allow_local::Bool, allow_almost::Bool}, Bool} where __T_settings}, WeightBounds{Float64, Float64}, Float64, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, ArithmeticReturn{Nothing, Nothing, Nothing}, SumScalariser, Nothing, Nothing, Int64, Int64, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, Nothing, Bool, Bool, Bool}, Variance{RiskMeasureSettings{Float64, Nothing, Bool}, Nothing, Nothing, Nothing, SquaredSOCRiskExpr}, __T_obj, Nothing, Nothing} where __T_obj}}}}}
cv ┼ KFold
│ n ┼ Int64: 5
│ purged_size ┼ Int64: 0
│ embargo_size ┴ Int64: 0
r ┼ MeanReturnRiskRatio
│ rt ┼ MeanReturn
│ │ w ┼ nothing
│ │ flag ┴ Bool: false
│ rk ┼ LowOrderMoment
│ │ settings ┼ RiskMeasureSettings
│ │ │ scale ┼ Float64: 1.0
│ │ │ ub ┼ nothing
│ │ │ rke ┴ Bool: true
│ │ w ┼ nothing
│ │ mu ┼ nothing
│ │ alg ┼ SecondMoment
│ │ │ ve ┼ SimpleVariance
│ │ │ │ me ┼ nothing
│ │ │ │ w ┼ nothing
│ │ │ │ corrected ┴ Bool: true
│ │ │ alg1 ┼ Full()
│ │ │ alg2 ┴ SquaredSOCRiskExpr()
│ rf ┴ Float64: 0.0
scorer ┼ HighestMeanScore()
ex ┼ Transducers.ThreadedEx{@NamedTuple{}}: Transducers.ThreadedEx()
n_iter ┼ Int64: 2
rng ┼ StableRNGs.LehmerRNG: StableRNGs.LehmerRNG(state=0x00000000000000000000000000000055)
seed ┼ nothing
train_score ┼ Bool: false
kwargs ┴ @NamedTuple{}: NamedTuple()As you can see the result contains sum([2x2, 2x1, 2x1, 2x1]) == 10 gridpoints.
rs_res1 = search_cross_validation(st, rs_cv1, rd)SearchCrossValidationResult
opt ┼ Stacking
│ pe ┼ EmpiricalPrior
│ │ ce ┼ PortfolioOptimisersCovariance
│ │ │ ce ┼ Covariance
│ │ │ │ me ┼ SimpleExpectedReturns
│ │ │ │ │ w ┴ nothing
│ │ │ │ ce ┼ GeneralCovariance
│ │ │ │ │ ce ┼ SimpleCovariance: SimpleCovariance(true)
│ │ │ │ │ w ┴ nothing
│ │ │ │ alg ┴ Full()
│ │ │ mp ┼ MatrixProcessing
│ │ │ │ pdm ┼ Posdef
│ │ │ │ │ alg ┼ UnionAll: NearestCorrelationMatrix.Newton
│ │ │ │ │ kwargs ┴ @NamedTuple{}: NamedTuple()
│ │ │ │ dn ┼ nothing
│ │ │ │ dt ┼ nothing
│ │ │ │ alg ┼ nothing
│ │ │ │ order ┴ NTuple{4, Symbol}: (:pdm, :dn, :dt, :alg)
│ │ me ┼ SimpleExpectedReturns
│ │ │ w ┴ nothing
│ │ horizon ┴ nothing
│ wb ┼ nothing
│ fees ┼ nothing
│ sets ┼ nothing
│ scale ┼ nothing
│ opti ┼ 2-element Vector{RiskJuMPOptimisationEstimator}
│ │ MeanRisk ⋯
│ │ RiskBudgeting ⋯
│ opto ┼ MeanRisk
│ │ opt ┼ JuMPOptimiser
│ │ │ pe ┼ EmpiricalPrior
│ │ │ │ ce ┼ PortfolioOptimisersCovariance
│ │ │ │ │ ce ┼ Covariance
│ │ │ │ │ │ me ┼ SimpleExpectedReturns
│ │ │ │ │ │ │ w ┴ nothing
│ │ │ │ │ │ ce ┼ GeneralCovariance
│ │ │ │ │ │ │ ce ┼ SimpleCovariance: SimpleCovariance(true)
│ │ │ │ │ │ │ w ┴ nothing
│ │ │ │ │ │ alg ┴ Full()
│ │ │ │ │ mp ┼ MatrixProcessing
│ │ │ │ │ │ pdm ┼ Posdef
│ │ │ │ │ │ │ alg ┼ UnionAll: NearestCorrelationMatrix.Newton
│ │ │ │ │ │ │ kwargs ┴ @NamedTuple{}: NamedTuple()
│ │ │ │ │ │ dn ┼ nothing
│ │ │ │ │ │ dt ┼ nothing
│ │ │ │ │ │ alg ┼ nothing
│ │ │ │ │ │ order ┴ NTuple{4, Symbol}: (:pdm, :dn, :dt, :alg)
│ │ │ │ me ┼ SimpleExpectedReturns
│ │ │ │ │ w ┴ nothing
│ │ │ │ horizon ┴ nothing
│ │ │ slv ┼ 7-element Vector{Solver}
│ │ │ │ Solver ⋯
│ │ │ │ Solver ⋯
│ │ │ │ Solver ⋯
│ │ │ │ Solver ⋯
│ │ │ │ Solver ⋯
│ │ │ │ Solver ⋯
│ │ │ │ Solver ⋯
│ │ │ wb ┼ WeightBounds
│ │ │ │ lb ┼ Float64: 0.0
│ │ │ │ ub ┴ Float64: 1.0
│ │ │ bgt ┼ Float64: 1.0
│ │ │ sbgt ┼ nothing
│ │ │ lt ┼ nothing
│ │ │ st ┼ nothing
│ │ │ lcse ┼ nothing
│ │ │ cte ┼ nothing
│ │ │ gcarde ┼ nothing
│ │ │ sgcarde ┼ nothing
│ │ │ smtx ┼ nothing
│ │ │ sgmtx ┼ nothing
│ │ │ slt ┼ nothing
│ │ │ sst ┼ nothing
│ │ │ sglt ┼ nothing
│ │ │ sgst ┼ nothing
│ │ │ tn ┼ nothing
│ │ │ fees ┼ nothing
│ │ │ sets ┼ nothing
│ │ │ tr ┼ nothing
│ │ │ ple ┼ nothing
│ │ │ ret ┼ ArithmeticReturn
│ │ │ │ ucs ┼ nothing
│ │ │ │ lb ┼ nothing
│ │ │ │ mu ┴ nothing
│ │ │ sca ┼ SumScalariser()
│ │ │ ccnt ┼ nothing
│ │ │ cobj ┼ nothing
│ │ │ sc ┼ Int64: 1
│ │ │ so ┼ Int64: 1
│ │ │ ss ┼ nothing
│ │ │ card ┼ nothing
│ │ │ scard ┼ nothing
│ │ │ nea ┼ nothing
│ │ │ l1 ┼ nothing
│ │ │ l2 ┼ nothing
│ │ │ linf ┼ nothing
│ │ │ lp ┼ nothing
│ │ │ brt ┼ Bool: false
│ │ │ cle_pr ┼ Bool: true
│ │ │ strict ┴ Bool: false
│ │ r ┼ Variance
│ │ │ settings ┼ RiskMeasureSettings
│ │ │ │ scale ┼ Float64: 1.0
│ │ │ │ ub ┼ nothing
│ │ │ │ rke ┴ Bool: true
│ │ │ sigma ┼ nothing
│ │ │ chol ┼ nothing
│ │ │ rc ┼ nothing
│ │ │ alg ┴ SquaredSOCRiskExpr()
│ │ obj ┼ MinimumRisk()
│ │ wi ┼ nothing
│ │ fb ┴ nothing
│ cv ┼ nothing
│ wf ┼ IterativeWeightFinaliser
│ │ iter ┴ Int64: 100
│ ex ┼ Transducers.ThreadedEx{@NamedTuple{}}: Transducers.ThreadedEx()
│ fb ┼ nothing
│ brt ┼ Bool: false
│ strict ┴ Bool: false
test_scores ┼ 5×10 Matrix{Float64}
train_scores ┼ nothing
lens_grid ┼ 10-element Vector{Vector{ComposedFunction{O, Accessors.PropertyLens{:opti}} where O}}
val_grid ┼ 10-element Vector{Tuple{Any, Vararg{Float64}}}
idx ┴ Int64: 6We can view the best indices and lenses, and that they match the chosen optimiser.
pretty_table(DataFrame("Lens" => rs_res1.lens_grid[rs_res1.idx],
"Value" => collect(rs_res1.val_grid[rs_res1.idx])))
for (lens, val) in zip(rs_res1.lens_grid[rs_res1.idx], rs_res1.val_grid[rs_res1.idx])
println("$(lpad("lens:", 12)) $lens\n$(lpad("val:", 12)) $val\n$(lpad("Field value:", 12)) $(lens(rs_res1.opt))\n")
end
res_rs1 = optimise(rs_res1.opt, rd)
plot_composition(res_rs1, rd)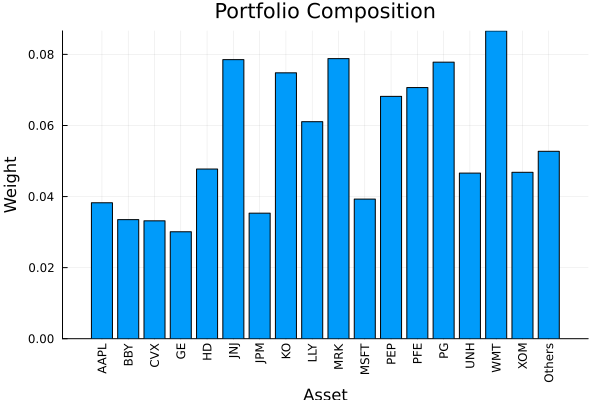
2.2.2 Sampling from a distribution
Now let's sample from a combination of the predefined parameter space and a distribution. We will sample 5 parameters from each. We don't need concrete_typed_array in RandomisedSearchCrossValidation as due to the need to accommodate Distributions.Distribution the checks cannot be performed at compile time, so they are performed at runtime.
p = [["opti[2].opt.l1" => range(; start = 0.0005, stop = 0.0008, length = 3),
"opti[1].opt.l2" => LogUniform(0.0003, 0.1)],
["opti[1].opt.l2" => LogUniform(0.001, 0.1)],
["opti[2].opt.l1" => range(; start = 0.0009, stop = 0.0012, length = 3)],
["opti[2]" => [MeanRisk(; opt = opt, obj = MaximumUtility()),
MeanRisk(; opt = opt, obj = MaximumRatio())]]]
rs_cv2 = RandomisedSearchCrossValidation(p; rng = StableRNG(42), r = r, n_iter = 5)RandomisedSearchCrossValidation
p ┼ 4-element Vector{Vector{Pair{String, Any}}}
cv ┼ KFold
│ n ┼ Int64: 5
│ purged_size ┼ Int64: 0
│ embargo_size ┴ Int64: 0
r ┼ MeanReturnRiskRatio
│ rt ┼ MeanReturn
│ │ w ┼ nothing
│ │ flag ┴ Bool: false
│ rk ┼ LowOrderMoment
│ │ settings ┼ RiskMeasureSettings
│ │ │ scale ┼ Float64: 1.0
│ │ │ ub ┼ nothing
│ │ │ rke ┴ Bool: true
│ │ w ┼ nothing
│ │ mu ┼ nothing
│ │ alg ┼ SecondMoment
│ │ │ ve ┼ SimpleVariance
│ │ │ │ me ┼ nothing
│ │ │ │ w ┼ nothing
│ │ │ │ corrected ┴ Bool: true
│ │ │ alg1 ┼ Full()
│ │ │ alg2 ┴ SquaredSOCRiskExpr()
│ rf ┴ Float64: 0.0
scorer ┼ HighestMeanScore()
ex ┼ Transducers.ThreadedEx{@NamedTuple{}}: Transducers.ThreadedEx()
n_iter ┼ Int64: 5
rng ┼ StableRNGs.LehmerRNG: StableRNGs.LehmerRNG(state=0x00000000000000000000000000000055)
seed ┼ nothing
train_score ┼ Bool: false
kwargs ┴ @NamedTuple{}: NamedTuple()The number of grid points is now sum([3x5, 5x1, 3x1, 2x1]) = 25, this is because vectors in a grid with a distribution are sampled with replacement (so n_iter samples can be taken from a vector whose length is < n_iter), and for vectors which are not in the same grid as a distribution sampling is done without replacement until the set is exhausted, so the number of samples is min(n_iter, length(list)).
rs_res2 = search_cross_validation(st, rs_cv2, rd)SearchCrossValidationResult
opt ┼ Stacking
│ pe ┼ EmpiricalPrior
│ │ ce ┼ PortfolioOptimisersCovariance
│ │ │ ce ┼ Covariance
│ │ │ │ me ┼ SimpleExpectedReturns
│ │ │ │ │ w ┴ nothing
│ │ │ │ ce ┼ GeneralCovariance
│ │ │ │ │ ce ┼ SimpleCovariance: SimpleCovariance(true)
│ │ │ │ │ w ┴ nothing
│ │ │ │ alg ┴ Full()
│ │ │ mp ┼ MatrixProcessing
│ │ │ │ pdm ┼ Posdef
│ │ │ │ │ alg ┼ UnionAll: NearestCorrelationMatrix.Newton
│ │ │ │ │ kwargs ┴ @NamedTuple{}: NamedTuple()
│ │ │ │ dn ┼ nothing
│ │ │ │ dt ┼ nothing
│ │ │ │ alg ┼ nothing
│ │ │ │ order ┴ NTuple{4, Symbol}: (:pdm, :dn, :dt, :alg)
│ │ me ┼ SimpleExpectedReturns
│ │ │ w ┴ nothing
│ │ horizon ┴ nothing
│ wb ┼ nothing
│ fees ┼ nothing
│ sets ┼ nothing
│ scale ┼ nothing
│ opti ┼ 2-element Vector{RiskJuMPOptimisationEstimator}
│ │ MeanRisk ⋯
│ │ RiskBudgeting ⋯
│ opto ┼ MeanRisk
│ │ opt ┼ JuMPOptimiser
│ │ │ pe ┼ EmpiricalPrior
│ │ │ │ ce ┼ PortfolioOptimisersCovariance
│ │ │ │ │ ce ┼ Covariance
│ │ │ │ │ │ me ┼ SimpleExpectedReturns
│ │ │ │ │ │ │ w ┴ nothing
│ │ │ │ │ │ ce ┼ GeneralCovariance
│ │ │ │ │ │ │ ce ┼ SimpleCovariance: SimpleCovariance(true)
│ │ │ │ │ │ │ w ┴ nothing
│ │ │ │ │ │ alg ┴ Full()
│ │ │ │ │ mp ┼ MatrixProcessing
│ │ │ │ │ │ pdm ┼ Posdef
│ │ │ │ │ │ │ alg ┼ UnionAll: NearestCorrelationMatrix.Newton
│ │ │ │ │ │ │ kwargs ┴ @NamedTuple{}: NamedTuple()
│ │ │ │ │ │ dn ┼ nothing
│ │ │ │ │ │ dt ┼ nothing
│ │ │ │ │ │ alg ┼ nothing
│ │ │ │ │ │ order ┴ NTuple{4, Symbol}: (:pdm, :dn, :dt, :alg)
│ │ │ │ me ┼ SimpleExpectedReturns
│ │ │ │ │ w ┴ nothing
│ │ │ │ horizon ┴ nothing
│ │ │ slv ┼ 7-element Vector{Solver}
│ │ │ │ Solver ⋯
│ │ │ │ Solver ⋯
│ │ │ │ Solver ⋯
│ │ │ │ Solver ⋯
│ │ │ │ Solver ⋯
│ │ │ │ Solver ⋯
│ │ │ │ Solver ⋯
│ │ │ wb ┼ WeightBounds
│ │ │ │ lb ┼ Float64: 0.0
│ │ │ │ ub ┴ Float64: 1.0
│ │ │ bgt ┼ Float64: 1.0
│ │ │ sbgt ┼ nothing
│ │ │ lt ┼ nothing
│ │ │ st ┼ nothing
│ │ │ lcse ┼ nothing
│ │ │ cte ┼ nothing
│ │ │ gcarde ┼ nothing
│ │ │ sgcarde ┼ nothing
│ │ │ smtx ┼ nothing
│ │ │ sgmtx ┼ nothing
│ │ │ slt ┼ nothing
│ │ │ sst ┼ nothing
│ │ │ sglt ┼ nothing
│ │ │ sgst ┼ nothing
│ │ │ tn ┼ nothing
│ │ │ fees ┼ nothing
│ │ │ sets ┼ nothing
│ │ │ tr ┼ nothing
│ │ │ ple ┼ nothing
│ │ │ ret ┼ ArithmeticReturn
│ │ │ │ ucs ┼ nothing
│ │ │ │ lb ┼ nothing
│ │ │ │ mu ┴ nothing
│ │ │ sca ┼ SumScalariser()
│ │ │ ccnt ┼ nothing
│ │ │ cobj ┼ nothing
│ │ │ sc ┼ Int64: 1
│ │ │ so ┼ Int64: 1
│ │ │ ss ┼ nothing
│ │ │ card ┼ nothing
│ │ │ scard ┼ nothing
│ │ │ nea ┼ nothing
│ │ │ l1 ┼ nothing
│ │ │ l2 ┼ nothing
│ │ │ linf ┼ nothing
│ │ │ lp ┼ nothing
│ │ │ brt ┼ Bool: false
│ │ │ cle_pr ┼ Bool: true
│ │ │ strict ┴ Bool: false
│ │ r ┼ Variance
│ │ │ settings ┼ RiskMeasureSettings
│ │ │ │ scale ┼ Float64: 1.0
│ │ │ │ ub ┼ nothing
│ │ │ │ rke ┴ Bool: true
│ │ │ sigma ┼ nothing
│ │ │ chol ┼ nothing
│ │ │ rc ┼ nothing
│ │ │ alg ┴ SquaredSOCRiskExpr()
│ │ obj ┼ MinimumRisk()
│ │ wi ┼ nothing
│ │ fb ┴ nothing
│ cv ┼ nothing
│ wf ┼ IterativeWeightFinaliser
│ │ iter ┴ Int64: 100
│ ex ┼ Transducers.ThreadedEx{@NamedTuple{}}: Transducers.ThreadedEx()
│ fb ┼ nothing
│ brt ┼ Bool: false
│ strict ┴ Bool: false
test_scores ┼ 5×25 Matrix{Float64}
train_scores ┼ nothing
lens_grid ┼ 25-element Vector{Vector{ComposedFunction{O, Accessors.PropertyLens{:opti}} where O}}
val_grid ┼ 25-element Vector{Tuple{Any, Vararg{Float64}}}
idx ┴ Int64: 4We can view the best indices and lenses, and that they match the chosen optimiser.
pretty_table(DataFrame("Lens" => rs_res2.lens_grid[rs_res2.idx],
"Value" => collect(rs_res2.val_grid[rs_res2.idx])))
for (lens, val) in zip(rs_res2.lens_grid[rs_res2.idx], rs_res2.val_grid[rs_res2.idx])
println("$(lpad("lens:", 12)) $lens\n$(lpad("val:", 12)) $val\n$(lpad("Field value:", 12)) $(lens(rs_res2.opt))\n")
end
res_rs2 = optimise(rs_res2.opt, rd)
plot_composition(res_rs2, rd)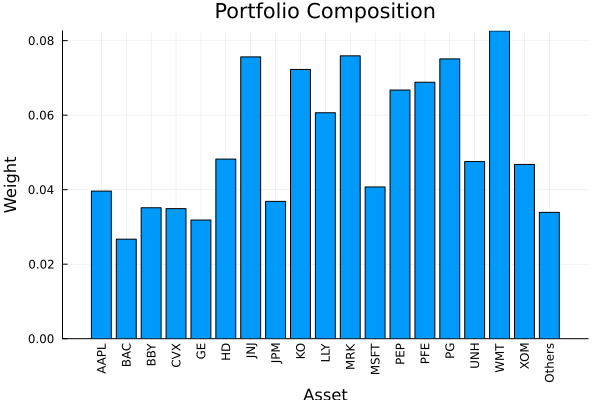
Comparing the three best portfolios — grid search, randomised (predefined), randomised (distribution) — shows how different hyperparameter budgets and sampling strategies affect the final allocation.
plot_stacked_bar_composition([res_gs1, res_rs1, res_rs2], rd)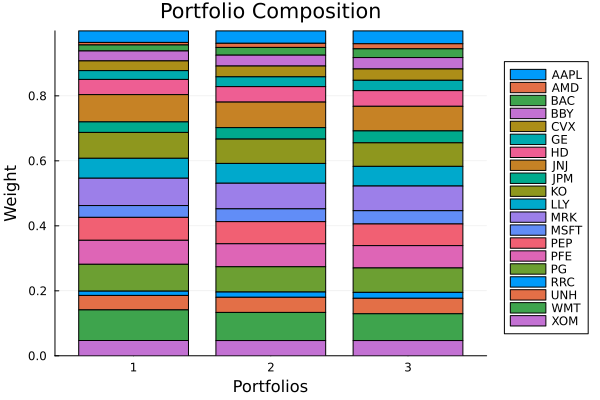
The hyperparameter tuning can be used on any non finite optimisation estimator. In the future it will also be possible to provide a pipeline which will also allow users to tune pre-selection criteria.
This page was generated using Literate.jl.